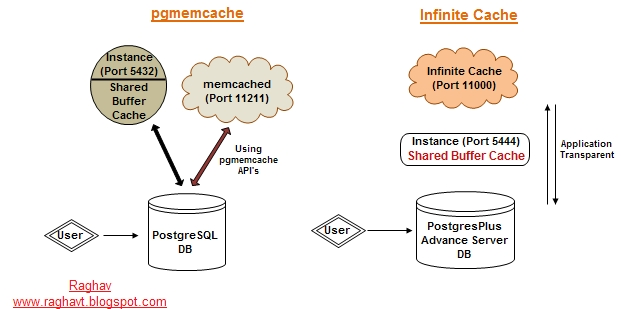
Caching...!!, its little bit hard to go in brief with single article. But will try to share my knowledge learnt from
Heikki / Robert Haas / Bruce Momjian in short. In PostgreSQL, there are two layers, PG shared buffers and OS Page cache, any read/write should pass through OS cache(No bypassing till now). Postgres writes data on OS Page Cache and confirms to user as it has written to disk, later OS cache write's to physical disk in its own pace. PG shared buffers has no control over OS Page Cache and it not even know what's in OS cache. So, most of the recommendation's given by Postgres DBA's/Professional's to have faster DISK / better cache.
Caches/buffers in PostgreSQL are stronger like other databases and highly sophisticated. As am from Oracle background (mindset also…:) ), so, my question's from whom I learnt was how/when/what/why etc., regarding Database buffer cache, pinned buffers, Flushing database buffers cache, preloading database etc., I got all my answers from them, however, the approach is bit different. Though my questions were bugging, they answered with great patience and clarifying me to good extent which in result you are reading this blog.... :)..
On some learnings(still learning), I drawn a small overview of how data flow between Memory to Disk in Postgres and also some of the important tools and NEW patch by
Robert Haas(pg_prewarm).
pg_buffercacheA contrib module, which tells whats in PostgreSQL buffer cache. Installation below:-
postgres=# CREATE EXTENSION pg_buffercache;
pgfincoreIt has a functionality to give the information about what data in OS Page Cache. Pgfincore, module become's very handy when it is clubbed with pg_buffercache, now one can get PG buffer cache & OS Page Cache information together. Thanks to
Cerdic Villemain. Pgfincore, backbone is fadvise, fincore which are linux ftools. You can also use fincore/fadvise by installing source. Two thing, you can use pgfincore contrib module or ftools both result the same. I tried both, they are simply awesome.
Installation:
Download the latest version: http://pgfoundry.org/frs/download.php/3186/pgfincore-v1.1.1.tar.gz
As root user:
export PATH=/usr/local/pgsql91/bin:$PATH //Set the path to point pg_config.
tar -xvf pgfincore-v1.1.1.tar.gz
cd pgfincore-1.1.1
make clean
make
make install
Now connect to PG and run below command
postgres=# CREATE EXTENSION pgfincore;
pg_prewarmPreloading the relation/index into PG buffer cache. Is it possible in PostgreSQL? oh yes, Thanks to
Robert Haas, who has recently submitted patch to community, hopefully it might be available in PG 9.2 or PG 9.3. However, you can use the patch for your testing on PG 9.1.
pg_prewarm has three MODE's:
- PREFETCH: Fetching data blocks asynchronously into OS cache only not into PG buffers (hits OS cache only)
- READ: Reads all the blocks into dummy buffer and forces into OS cache. (hits OS cache only)
- BUFFER: reads all the blocks or range of blocks into database buffer cache.
Installation:I am applying pg_prewarm patch on my PG source installation, you need to tweak as per your setup.
- Untar location of PG source : /usr/local/src/postgresql-9.1.3
- PG installation locatin : /usr/local/pgsql91
- All downloads Location : /usr/local/src
Note: Install PG before applying pg_prewarm patch.
1. Download the patch to /usr/local/src/ location
http://archives.postgresql.org/pgsql-hackers/2012-03/binRVNreQMnK4.binPatch attached Email:
http://archives.postgresql.org/message-id/CA+TgmobRrRxCO+t6gcQrw_dJw+Uf9ZEdwf9beJnu+RB5TEBjEw@mail.gmail.com2. After download go to PG source location and follow the steps.
# cd /usr/local/src/postgresql-9.1.3
# patch -p1 < ../pg_prewarm.bin (I have renamed after download)
# make -C contrib/pg_prewarm
# make -C contrib/pg_prewarm install
3. Above command will create files under $PGPATH/contrib/extension. Now you are ready to add the contrib module.
postgres=# create EXTENSION pg_prewarm;
CREATE EXTENSION
postgres=# \dx
List of installed extensions
Name | Version | Schema | Description
----------------+---------+------------+----------------------------------------
pg_buffercache | 1.0 | public | examine the shared buffer cache
pg_prewarm | 1.0 | public | prewarm relation data
pgfincore | 1.1.1 | public | examine and manage the os buffer cache
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(4 rows)
Documentation:
/usr/local/src/postgresql-9.1.3/doc/src/sgml
[root@localhost sgml]# ll pgpre*
-rw-r--r-- 1 root root 2481 Apr 10 10:15 pgprewarm.sgml
dstatA combination of vmstat,iostat,netstat,top,etc., tool together in one "dstat" linux command. When database behaving unusually, to know the cause from OS level, we open couple of terminals to pull process, memory,disk read/writes, network informations, which is little bit pain to shuffle between windows. So, dstat has serveral options with in it, which helps to show all commands in one output one window.
Installation:
Dstat download link: (RHEL 6)
wget http://pkgs.repoforge.org/dstat/dstat-0.7.2-1.el6.rfx.noarch.rpm
or
yum install dstat
Documentation: http://dag.wieers.com/home-made/dstat/
Linux ftoolsIts designed for working with modern linux system calls including, mincore, fallocate, fadvise, etc. Ftools, will help you to figure out what files are in OS cache. Using perl/python scripts you can retrieve OS page cache information on object files (pg_class.relfilenode). pg_fincore is based on this. You can use pgfincore or ftools scripts.
Installation:
Download the tar.gz from the link.
https://github.com/david415/python-ftools
cd python-ftools
python setup.py build
export PYTHONPATH=build/lib.linux-x86_64-2.5
python setup.py install
Note: You need to have python & psycopg2 installed before installing python-ftools.
Now, we are all set to proceed with example to check with the tools & utilities. In my example, I have a table, it has one index & sequence with 100+ MB of data in it.
postgres=# \d+ cache
Table "public.cache"
Column | Type | Modifiers | Storage | Description
--------+---------+-----------------------------------------+----------+-------------
name | text | | extended |
code | integer | | plain |
id | integer | default nextval('icache_seq'::regclass) | plain |
Indexes:
"icache" btree (code)
Has OIDs: no
Query to know the size occupied by table,sequence and its index.
postgres=# SELECT c.relname AS object_name,
CASE when c.relkind='r' then 'table'
when c.relkind='i' then 'index'
when c.relkind='S' then 'sequence'
else 'others'
END AS type,pg_relation_size(c.relname::text) AS size, pg_size_pretty(pg_relation_size(c.relname::text)) AS pretty_size
FROM pg_class c
JOIN pg_roles r ON r.oid = c.relowner
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE (c.relkind = ANY (ARRAY['r'::"char", 'i'::"char", 'S'::"char",''::"char"])) AND n.nspname = 'public';
object_name | type | size | pretty_size
-------------+----------+----------+-------------
icache_seq | sequence | 8192 | 8192 bytes
cache | table | 83492864 | 80 MB
icache | index | 35962880 | 34 MB
(3 rows)
Total object size 'cache'
postgres=# select pg_size_pretty(pg_total_relation_size('cache'));
pg_size_pretty
----------------
114 MB
(1 row)
I have written small query by clubbing pgfincore and pg_buffercache to pull information from PG Buffer & OS Page cache. I will be using this query through out my example, only pasting this query outputs.
select rpad(c.relname,30,' ') as Object_Name,
case when c.relkind='r' then 'Table' when c.relkind='i' then 'Index' else 'Other' end as Object_Type,
rpad(count(*)::text,5,' ') as "PG_Buffer_Cache_usage(8KB)",
split_part(pgfincore(c.relname::text)::text,','::text,5) as "OS_Cache_usage(4KB)"
from pg_class c inner join pg_buffercache b on b.relfilenode=c.relfilenode
inner join pg_database d on (b.reldatabase=d.oid and d.datname=current_database() and c.relnamespace=(select oid from pg_namespace where nspname='public'))
group by c.relname,c.relkind
order by "PG_Buffer_Cache_usage(8KB)"
desc limit 10;
object_name | object_type | PG_Buffer_Cache_usage(8KB) | OS_Cache_usage(4KB)
-------------+-------------+----------------------------+---------------------
(0 rows)
Note: I have bounced the cluster to flush PG buffers & OS Page Cache. So, no data in any Cache/buffer.
Preloading relation/index using pg_prewarm:Before, bouncing the cluster I have fired full table sequential scan query on "Cache" table, and noted the time which is before warming the relation/index.
postgres=# explain analyze select * from cache ;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------
Seq Scan on cache (cost=0.00..26192.00 rows=1600000 width=19) (actual time=0.033..354.691 rows=1600000 loops=1)
Total runtime: 427.769 ms
(2 rows)
Lets warm relation/index/sequence using pg_prewarm and check query plan.
postgres=# select pg_prewarm('cache','main','buffer',null,null);
pg_prewarm
------------
10192
(1 row)
postgres=# select pg_prewarm('icache','main','buffer',null,null);
pg_prewarm
------------
4390
(1 row)
Output of combined buffers:
object_name | object_type | PG_Buffer_Cache_usage(8KB) | OS_Cache_usage(4KB)
-------------+-------------+----------------------------+---------------------
icache | Index | 4390 | 8780
cache | Table | 10192 | 20384
(2 rows)
pgfincore output: postgres=# select relname,split_part(pgfincore(c.relname::text)::text,','::text,5) as "In_OS_Cache" from pg_class c where relname ilike '%cache%';
relname | In_OS_Cache
------------+-------------
icache_seq | 2
cache | 20384
icache | 8780
(3 rows)
or for each object.
postgres=# select * from pgfincore('cache');
relpath | segment | os_page_size | rel_os_pages | pages_mem | group_mem | os_pages_free | databit
------------------+---------+--------------+--------------+-----------+-----------+---------------+---------
base/12780/16790 | 0 | 4096 | 20384 | 20384 | 1 | 316451 |
(1 row)
To retrieve similar information using python-ftools script you need to know objects relfilenode number, check below.
postgres=# select relfilenode,relname from pg_class where relname ilike '%cache%';
relfilenode | relname
-------------+----------------
16787 | icache_seq /// you can exclude sequence.
16790 | cache /// table
16796 | icache /// index
(3 rows)
using python-ftools script
Is it not interesting....!!!!.
Now compair the explain plan after warming table into buffer.
postgres=# explain analyze select * from cache ;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------
Seq Scan on cache (cost=0.00..26192.00 rows=1600000 width=19) (actual time=0.016..141.804 rows=1600000 loops=1)
Total runtime: 215.100 ms
(2 rows)
How to flush/prewarm relation/index in OS cache ?Using pgfadvise, you can preload or flush the relation from the OS cache. For more information, type \df pgfadvise* in terminal for all functions related to pgfadvise. Below is example of flushing the OS cache.
postgres=# select * from pgfadvise_dontneed('cache');
relpath | os_page_size | rel_os_pages | os_pages_free
------------------+--------------+--------------+---------------
base/12780/16790 | 4096 | 20384 | 178145
(1 row)
postgres=# select * from pgfadvise_dontneed('icache');
relpath | os_page_size | rel_os_pages | os_pages_free
------------------+--------------+--------------+---------------
base/12780/16796 | 4096 | 8780 | 187166
(1 row)
postgres=# select relname,split_part(pgfincore(c.relname::text)::text,','::text,5) as "In_OS_Cache" from pg_class c where relname ilike '%cache%';
relname | In_OS_Cache
------------+-------------
icache_seq | 0
cache | 0
icache | 0
(3 rows)
While these things are going on in one window you can check the read/write ratio by using dstat. For more options use dstat --list
dstat -s --top-io --top-bio --top-mem
Preloading Range of block's using pg_prewarm range functionality.Assume,due to some reason, you want to bounce the cluster, but one of big table which is in buffer is performing well. On bouncing, your table no more in buffers, to get back to original state as it was before bouncing then you have to know how many table blocks were there in buffers and preload them using pg_prewarm range option.
I have created a table by querying pg_buffercache and later I have sent block range information to pg_prewarm. By this, shared buffers is back with the table earlier loaded in it. See the example.
select c.relname,count(*) as buffers from pg_class c
inner join pg_buffercache b on b.relfilenode=c.relfilenode and c.relname ilike '%cache%'
inner join pg_database d on (b.reldatabase=d.oid and d.datname=current_database())
group by c.relname
order by buffers desc;
relname | buffers
---------+---------
cache | 10192
icache | 4390
(2 rows)
Note: These are the blocks in buffer.
postgres=# create table blocks_in_buff (relation, fork, block) as select c.oid::regclass::text, case b.relforknumber when 0 then 'main' when 1 then 'fsm' when 2 then 'vm' end, b.relblocknumber from pg_buffercache b, pg_class c, pg_database d where b.relfilenode = c.relfilenode and b.reldatabase = d.oid and d.datname = current_database() and b.relforknumber in (0, 1, 2);
SELECT 14716
Bounce the cluster and preload the range of blocks related to table into buffers from the "blocks_in_buff".
postgres=# select sum(pg_prewarm(relation, fork, 'buffer', block, block)) from blocks_in_buff;
sum
-------
14716
(1 row)
postgres=# select c.relname,count(*) as buffers from pg_class c
inner join pg_buffercache b on b.relfilenode=c.relfilenode and c.relname ilike '%cache%'
inner join pg_database d on (b.reldatabase=d.oid and d.datname=current_database())
group by c.relname
order by buffers desc;
relname | buffers
---------+---------
cache | 10192
icache | 4390
(2 rows)
See, my shared_buffer's is back in play.
Enjoy…!!! will be back with more interesting stuff. Do post your comments.
--Raghav